Building My First Three AI Agents
Building My First Three AI Agents

Day 2 was when Claude Code stopped being a tool and started being a system. I built three agents that, together, automated the bookends of my workday.
What's a Claude Code Agent?
An agent is a markdown file that defines a specialized persona. It has a system prompt, a list of available tools, trigger phrases, and instructions for how to behave. When you invoke an agent, Claude Code spawns a subprocess that runs autonomously — reading data, making decisions, and producing output.
The key difference from a skill: agents are autonomous. You launch them and they execute a multi-step workflow without hand-holding. Skills are invoked inline within a conversation.
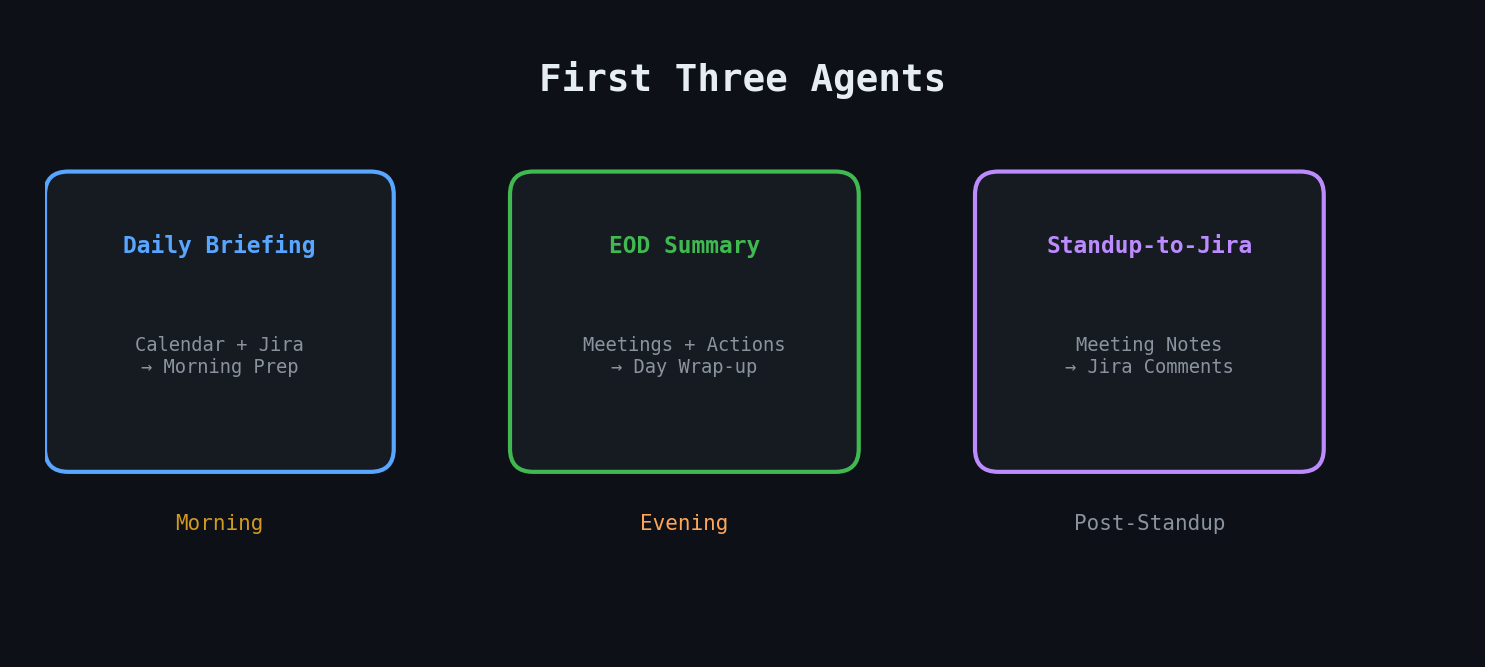
Agent 1: Morning Briefing
The `tpm-daily-assistant` agent reads my calendar, then enriches each meeting with context from Jira, Confluence, and Slack.
The workflow:
- Read today's calendar events
- For each meeting, pull relevant Jira tickets (sprint issues, roadmap initiatives)
- Search Confluence for related docs and decisions
- Search Slack for recent threads in project channels
- Generate a structured briefing with action items and prep notes
Before this agent, my morning routine was: open calendar, open Jira, open Confluence, open Slack, cross-reference mentally for 90 minutes. Now it's: type "prep my day", wait 2 minutes, read the briefing.
Agent 2: EOD Summary
The `tpm-eod-summary` agent synthesizes the day's work. It reads AI-generated meeting notes from the day, cross-references action items from the morning briefing, and produces a summary with:
- What was accomplished
- Open items carrying over
- Tomorrow's preview with connections to today's decisions
The key insight was cross-referencing. The EOD agent doesn't just list meetings — it checks whether morning action items were addressed, flags anything that stalled, and connects today's outcomes to tomorrow's agenda.
Agent 3: Standup Sync
The `standup-note-to-jira` agent solves a specific pain point: after standup meetings, someone captures notes in a Google Doc. Those notes reference Jira tickets, but nobody updates the tickets with the discussed context.
This agent:
- Finds today's standup notes (auto-generated by Google's Gemini)
- Parses the content for Jira ticket references
- Matches them against the active sprint
- Drafts comments for each ticket with relevant context
- Shows me a preview and waits for approval before posting
It never posts without asking — a safety rule baked into the agent's instructions.
The Memory System
On Day 2, I also created the memory system. Claude Code has a `MEMORY.md` file that persists across conversations. I started capturing:
- Project context (what's the current sprint, what meetings recur weekly)
- Key reference data (Jira project keys, Confluence space IDs)
- Learned patterns ("Glean search works best with short keyword queries")
This turned out to be critical. Without persistent memory, every new session starts from zero. With it, the agent ecosystem builds institutional knowledge over time.
The Report Pipeline
Every agent saves its output to `~/Reports/{subfolder}/` with a date-stamped filename, then uploads to Google Drive. This gives me:
- Local files for quick reference and grep
- Drive sync for access from any device
- Historical archive for tracking patterns over time
``` ~/Reports/ daily-briefings/ tpm-daily-briefing-2026-02-21.md eod-summaries/ tpm-eod-summary-2026-02-21.md standup-notes/ standup-note-2026-02-21.md ```
Cost Reality Check
Day 2 cost $89. That's 3x Day 1. Building and testing agents is expensive — each test run dispatches a subprocess that reads from multiple MCP sources, processes context, and generates output. Opus-class models aren't cheap.
But the math works out. If these three agents save me 2 hours per day, that's 40+ hours per month of TPM time recovered.
Key Takeaways
- Agents are autonomous workflows, not chat interactions — design them with clear inputs, steps, and outputs
- Cross-referencing across sources (calendar + Jira + Slack) is where agents create real value
- Persistent memory (`MEMORY.md`) prevents the AI from forgetting everything between sessions
- Always build a save-first pipeline — local file before cloud upload, previews before posting
- Agent development is expensive in the exploration phase — costs stabilize once agents are production-ready