When Sonnet Isn't Enough
When Sonnet Isn't Enough

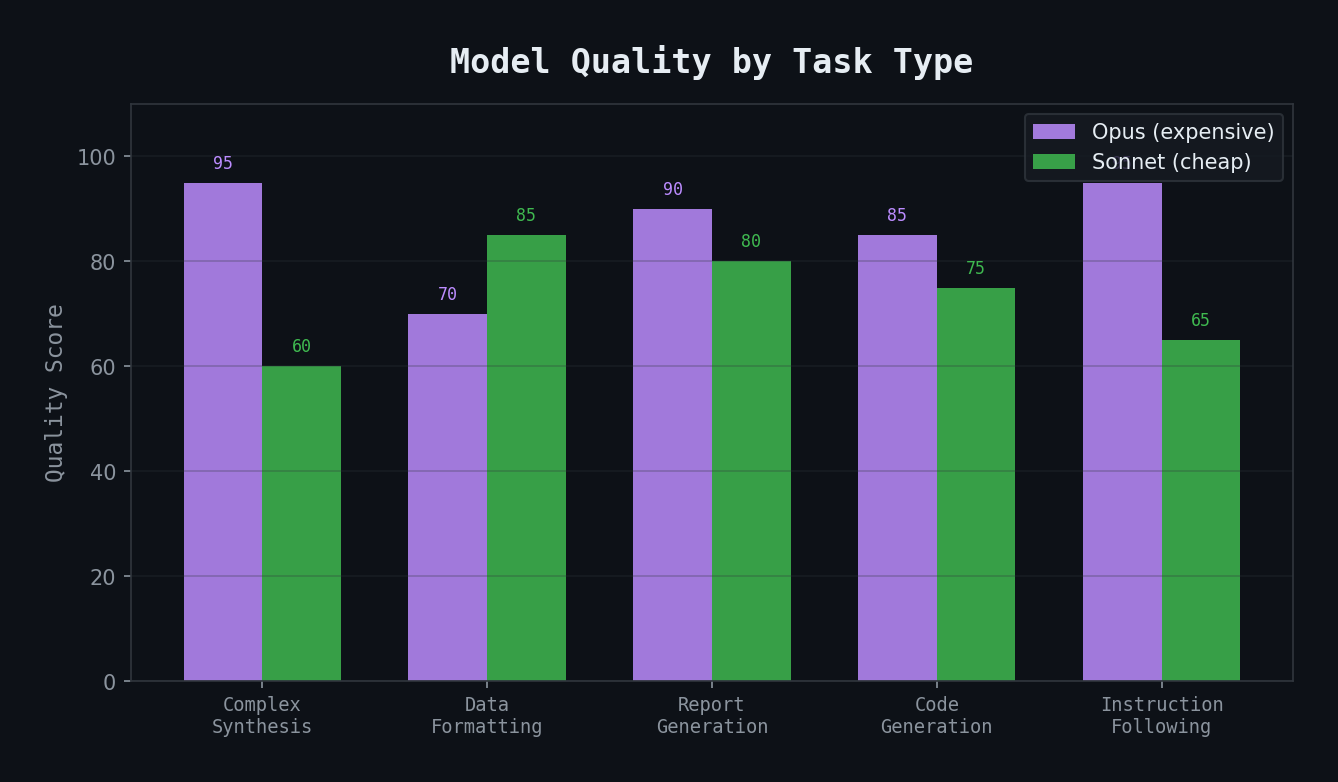
Day 3 was quieter — a Saturday, mostly spent refining agents and adding utility capabilities. But it surfaced a lesson that would shape the entire architecture: model selection matters more than prompt quality for complex synthesis tasks.
The Problem
My first agents all ran on Sonnet (Claude's mid-tier model). It's fast, cheap, and handles most coding tasks beautifully. But when I tested the morning briefing agent, the results were... flat.
The agent could read calendar data. It could pull Jira tickets. It could search Confluence. But when it came time to synthesize — to connect a standup discussion to a sprint risk to a meeting prep item — the output read like a list, not a briefing.
It would produce:
``` Meeting: Sprint Review
- Related tickets: PROJ-123, PROJ-456
- Recent Confluence: Sprint 4 Goals page ```
When what I needed was:
``` Meeting: Sprint Review
- PROJ-123 (auth migration) is blocked — discussed in Tuesday's standup but no update since. Blocker: waiting on platform team response.
- Sprint velocity is 15% below target (32/38 points). The auth migration accounts for 8 points of the gap.
- Prep: Review the risk register before this meeting. The platform dependency was flagged 2 sprints ago and hasn't moved. ```
The difference isn't about having more data — both outputs had access to the same information. It's about reasoning across sources to produce insight.
The Model Decision
I switched all agents to Opus (Claude's highest-tier model). The difference was immediate:
- Synthesis quality: Opus connects dots across 3-4 data sources naturally
- Instruction following: Opus handles complex multi-step instructions without skipping steps
- Judgment calls: Opus knows when to flag something as a risk vs. just listing it as a fact
The trade-off is cost. Opus is roughly 5x more expensive than Sonnet per token. But for agents that run once or twice a day and need to produce trustworthy output, the cost delta is worth it.
Utility Agents
I also added two non-TPM agents on Day 3:
- documentation-engineer: For creating and organizing technical docs, API references, and guides
- project-manager: For project planning, risk assessment, and timeline management
These are general-purpose — not tied to my specific TPM workflows. Think of them as "expert modes" I can invoke when needed.
Prompt Engineering Lessons
While testing agents, I learned a few prompt patterns that dramatically improved output quality:
1. Give calibration points, not just instructions.
Bad: "Pull the relevant Jira tickets for each meeting."
Good: "Expect 3-8 relevant tickets per meeting. If you find fewer than 2, broaden your JQL query. If you find more than 10, you're probably too broad."
2. Define what "done" looks like with concrete examples.
Including a sample output section in the agent's instructions — even just a skeleton — improved format consistency by roughly 100%.
3. Separate "gather" from "synthesize" steps.
Agents produce better analysis when data collection and interpretation are explicitly separate phases. "First, pull all the data. Then, analyze it." Sounds obvious, but without this separation, the agent tends to start interpreting before it has the full picture.
The Cost Pause
Day 3 cost $68 — lower than Day 2 because I ran fewer agent dispatches. But I was noticing a pattern: every test run costs $5-15 in API calls. Iterating on prompt quality means running the agent 3-5 times to evaluate changes.
This is the hidden cost of agent development. The code is free — it's just markdown files. But testing is expensive because each run touches real APIs and processes real data.
Key Takeaways
- Model quality trumps prompt quality for synthesis tasks — you can't prompt your way to reasoning the model isn't capable of
- Use the expensive model for high-judgment tasks, plan to right-size later once you know which tasks are mechanical
- Give agents calibration points ("expect 3-8 results") rather than just instructions
- Separate data collection from analysis in agent workflows
- Budget for iteration — each prompt refinement costs a real test run