The Orchestrator Pattern
The Orchestrator Pattern
By Day 4, I had a problem. I had 8+ agents, each doing one thing well. But my actual needs were compound: "Get me caught up on everything" isn't one agent's job — it's three agents running in parallel.
The Problem with Flat Agent Architecture
With individual agents, my morning routine looked like:
- "Prep my day" → wait 2 minutes
- "DCT check" → wait 3 minutes
- "Sprint update" → wait 1 minute
- Read three separate reports and mentally merge them
Total: ~8 minutes of waiting plus mental synthesis. Better than 2 hours of manual work, but still inefficient.
Enter the Orchestrator
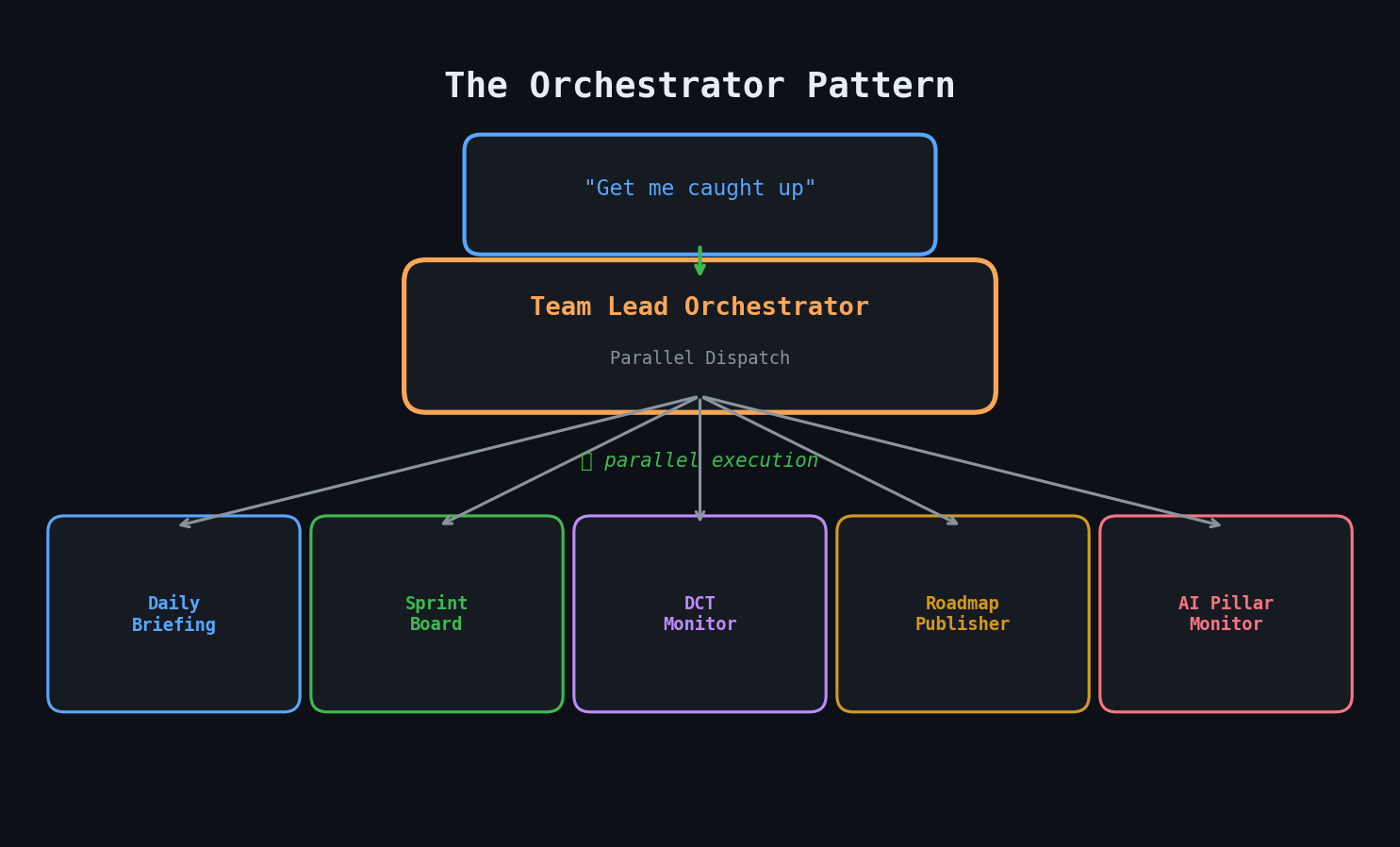
I created the `tpm-team-lead` agent — an orchestrator that doesn't do work itself. Instead, it dispatches specialist agents in parallel and synthesizes their results.
The key innovation: compound request recognition. When I say "get me caught up", the team lead identifies that this means:
- Launch `tpm-daily-assistant` (morning briefing)
- Launch `dct-program-monitor` (cross-team program status)
- Launch `daily-update-publisher` (sprint standup text)
All three run concurrently. The team lead waits for all results, then produces a unified summary.
Compound Workflows
I defined six standard compound workflows:
| Trigger | Agents Dispatched |
|---|---|
| "Morning routine" | daily-assistant + sprint-board + DCT check |
| "Full status" | sprint-board + DCT monitor + roadmap |
| "Update all Confluence" | sprint-board + roadmap + tech-roadmap |
| "End of day" | EOD summary + daily-update |
| "End of week" | EOD + sprint-board + initiative check |
| "Post standup" | standup-note-to-jira + daily-update |
The DCT Program Monitor
Day 4 also saw the creation of my most ambitious agent: the `dct-program-monitor`. This agent monitors a cross-functional program by scanning:
- 10 Slack channels for recent activity, decisions, and blockers
- Jira roadmap initiatives filtered by program area
- Confluence tracking pages for status updates and risk registers
It cross-references everything and generates a digest with risk flags. If a Slack channel is buzzing about a blocker but the Jira ticket hasn't been updated, that gets flagged. If a roadmap initiative has no recent activity but its target date is approaching, that gets flagged.
This is the kind of agent that justifies Opus pricing. The cross-referencing and judgment calls require genuine reasoning, not just data retrieval.
Confluence Publishers
I also created four "publisher" agents that generate formatted reports for Confluence:
- sprint-board-publisher: Active sprint tickets grouped by status with metrics
- roadmap-publisher: Roadmap initiatives grouped by pillar and quarter
- tech-roadmap-publisher: Filtered view for technical leadership
- daily-update-publisher: Sprint standup text formatted for Slack
These are mechanical agents — pull data, format it, publish. No complex reasoning required. (This distinction would matter later when I started optimizing costs.)
Architecture: Sequential to Hierarchical
``` Before (Day 2): User → Agent A → result User → Agent B → result User → Agent C → result
After (Day 4): User → Team Lead → [Agent A, Agent B, Agent C] → synthesized result ```
The hierarchical pattern has three advantages:
- Parallelism: Independent agents run concurrently
- Synthesis: One place to merge cross-agent insights
- Simplicity: User remembers one trigger phrase, not twelve
The Cost of Ambition
Day 4 cost $160. The DCT program monitor alone costs ~$15 per run because it reads from 10+ sources. The orchestrator pattern adds overhead by spawning multiple agents per request.
But this was the day the system became genuinely useful. One command, one wait, one result — covering three workstreams simultaneously.
Key Takeaways
- Flat agent architectures don't scale — compound needs require an orchestration layer
- The orchestrator should dispatch and synthesize, not do domain work itself
- Parallel execution matters — 3 agents in parallel beats 3 agents in sequence
- Cross-referencing across sources (Slack + Jira + Confluence) is where program monitoring agents create unique value
- Distinguish "reasoning" agents from "formatting" agents early — it affects model selection and cost