Cutting Costs by 40%: CLI Tools and Model Tiering
Cutting Costs by 40%: CLI Tools and Model Tiering
Day 8 was the payoff. After 7 days of building, breaking, and fixing, it was time to optimize. The goal: reduce costs without reducing quality.
The Cost Problem
My agent ecosystem was running roughly $333/week on a path to $1,400/month. For a personal productivity tool, that's significant. The breakdown revealed two major cost drivers:
- All agents running on Opus (~5x the cost of Sonnet)
- Failed runs requiring retries (auth expiry, search failures, incomplete results)
The retry problem was especially insidious. My daily briefing agent was dispatched 11 times across 4 days — it should have been dispatched 4 times. Nearly 3x the expected cost, all because of data source reliability issues.
Fix 1: Direct CLI Tools
My enterprise search platform (Glean MCP) had a fundamental reliability problem: auth tokens expired every hour. This caused:
- Silent failures where agents proceeded with no data
- Retry loops that multiplied costs
- Inconsistent results depending on when the token was last refreshed
The fix was replacing Glean with a direct CLI tool (`desk`) for Google Workspace access. This CLI uses OAuth refresh tokens that never expire — no manual re-authentication needed.
I updated four agents to use the new CLI as their primary data source:
| Agent | Data Source | Result |
|---|---|---|
| Daily briefing | Calendar, sheets, docs | 52% fewer tokens (47K vs 98K) |
| EOD summary | Calendar, meeting notes | 3/3 notes found (vs 0/3 with expired auth) |
| Standup sync | Meeting notes | First-try success (vs retry failures) |
| Program monitor | Weekly huddle notes | Reliable retrieval |
The token reduction alone was significant — the briefing agent was consuming 98K tokens per run with Glean (bloated response metadata) vs 47K with direct CLI access.
Fix 2: Model Tiering
Not every agent needs Opus. The insight from Day 3 was that synthesis tasks need Opus but mechanical tasks don't. Day 8 was when I actually applied this:
Kept on Opus (complex reasoning, cross-source synthesis):
- Daily briefing — synthesizes calendar + Jira + Slack + Confluence
- EOD summary — cross-references meetings, action items, and tomorrow's context
- DCT program monitor — scans 10 channels, cross-references with Jira
- AI pillar monitor — scans 8 channels, reads 7 Confluence pages
Switched to Sonnet (structured data formatting, template-driven output):
- Sprint board publisher — pull Jira data, format as table
- Roadmap publisher — pull initiatives, group by pillar/quarter
- Daily update publisher — format sprint tickets as Slack text
- Initiative notes checker — parse fields, classify freshness
- Standup sync — match notes to tickets, format comments
The rule: if an agent's job is "pull data and format it," Sonnet is fine. If its job is "read from 5 sources and tell me what matters," it needs Opus.
Fix 3: Session Consolidation
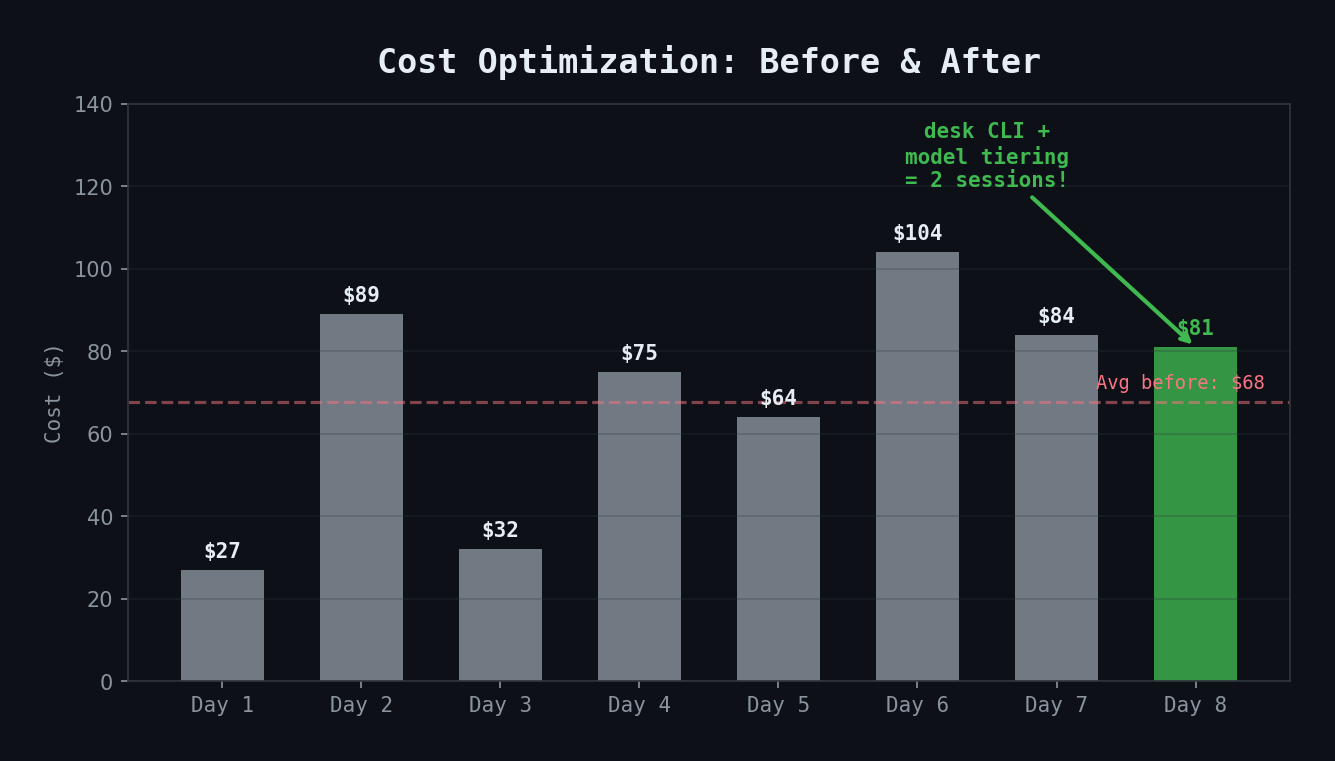
Day 7 had 21 sessions. Each new session costs ~$3 in cache creation overhead (loading CLAUDE.md, MEMORY.md, and other context into the model's cache). Twenty-one sessions meant ~$63 just in startup costs.
Day 8: 2 sessions. Same work output.
The trick is using longer sessions with Claude Code's `/clear` command (which resets conversation context without closing the session) instead of opening new terminal windows.
The Numbers
| Metric | Before (Day 7) | After (Day 8) | Change |
|---|---|---|---|
| Sessions/day | 21 | 2 | -90% |
| Daily briefing tokens | 98K | 47K | -52% |
| EOD notes retrieval | 0/3 (expired auth) | 3/3 | 100% reliability |
| Projected weekly cost | ~$333 | ~$200 | -40% |
Data Source Reliability Scorecard
After a week of real-world usage, here's how the three data source integrations stacked up:
| Source | Auth | Accuracy | Uptime | Token Efficiency |
|---|---|---|---|---|
| Direct CLI (desk) | A+ (never expires) | A+ (no truncation) | 100% | A+ (15-52% fewer tokens) |
| Atlassian MCP | A (stable) | A (direct API) | ~95% | B+ (ADF is verbose) |
| Enterprise Search (Glean) | D (hourly expiry) | B- (truncates/summarizes) | ~65% | C (bloated metadata) |
The enterprise search platform still has one exclusive capability: Slack channel searches. There's no alternative for that. But for everything else — calendars, docs, sheets, drive — the direct CLI tool is strictly superior.
The Final Architecture
``` Day 1: 0 agents, 0 skills, $0 infrastructure Day 8: 17 agents, 35 skills, 3 data sources, ~$200/week
Routing: desk > Atlassian MCP > Glean (fallback only) Models: Opus (synthesis) + Sonnet (formatting) Dispatch: Hierarchical (team-lead orchestrator → specialists) Memory: Persistent MEMORY.md + agent-changelog.md Reports: Local first → Drive sync ```
Key Takeaways
- Direct API access beats middleware every time — fewer tokens, no auth expiry, no truncation
- Model tiering is the single biggest cost lever — Opus for reasoning, Sonnet for formatting
- Session consolidation eliminates cache creation overhead — 2 long sessions beats 20 short ones
- Reliability improvements compound — fixing retries alone saves 3x on affected agents
- Track data source reliability as a first-class metric — it directly drives agent cost through retry volume
- Optimize last, not first — you need to build and break things before you know what to optimize