Week 2: Building a TPM AI Operating System
Week 2: Building a TPM AI Operating System
Theme: Portfolio intelligence, organizational knowledge automation, and hitting tool boundaries.
Part of the TPM Agent Ecosystem build log. ← Week 1: Building the Foundation
Week 1 was plumbing — daily briefings, sprint publishers, standup-to-Jira sync. Week 2 shifted toward deeper intelligence: portfolio-level analysis, organizational wiki hygiene, and enriching my agent fleet with institutional knowledge. This week also brought the clearest lessons yet about tool limits and when to step back from automation.
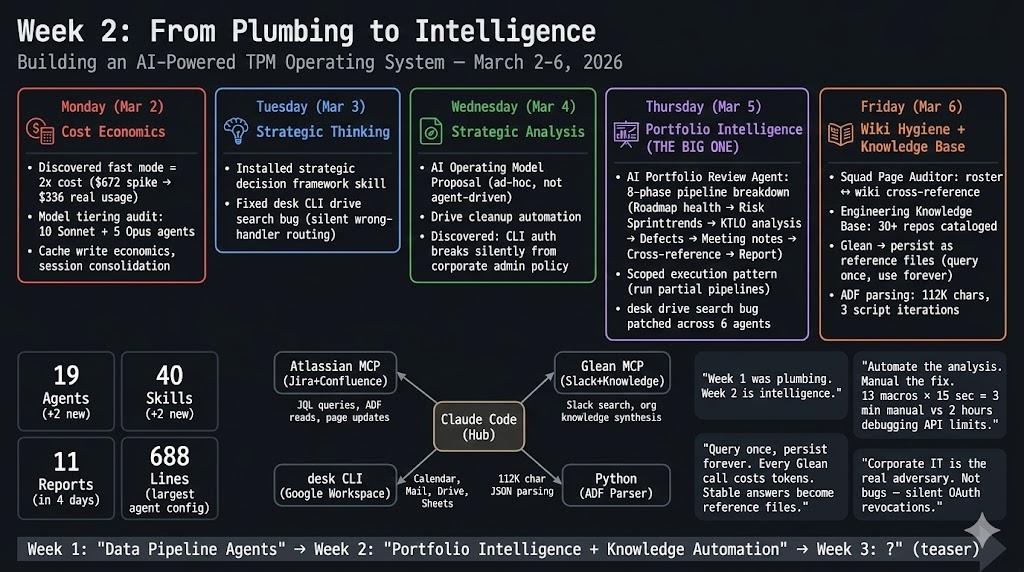
Monday — Cost Economics + Token Optimization
Fast mode doubles the cost for zero agent benefit. Claude Code fast mode charges $30/$150 per Mtok vs $15/$75 standard. The irony: agents don't benefit from faster streaming — you wait for the full result either way. Turned it off everywhere.
Cache writes cost tokens; cache reads are nearly free. Every new terminal session creates $3–4 in cache overhead. Fix: use /clear instead of opening new terminals.
Tuesday — Strategic Thinking Frameworks
Day 2 was the first time I used Claude Code purely as a thinking tool rather than a building tool.
I installed a strategic decision framework skill — not an agent, but a reusable thinking scaffold that enforces first-principles analysis, 80/20 prioritization, systems thinking, and expert simulation before drawing conclusions. TPMs notoriously skip structured analysis under time pressure. This is the forcing function.
I also hit my first silent-failure bug: a CLI tool we use for Google Workspace integration routes freetext queries to the email handler, not Drive. So "meeting notes" searched email. name contains 'meeting notes' searched Drive. No error. No warning. Just wrong data. This bug would take until Thursday to fully scope — it affected 6 agents.
Wednesday — AI Operating Model + Drive Cleanup
Used Claude Code as a strategic analysis tool to draft an operating model proposal for my AI pillar — not agent-driven, pure conversational synthesis of organizational patterns, meeting structures, and governance gaps. 3 of 11 reports this week were non-agent, ad-hoc analysis. The fleet is becoming a general strategic tool, not just a reporting system.
Second silent-failure lesson: OAuth refresh tokens theoretically never expire. But corporate Google Workspace admins can revoke app access at any time. The CLI returns "No credentials found" — no error code, no "auth revoked" message. I spent 30 minutes debugging before discovering the admin had restricted the OAuth app.
Thursday — The AI Portfolio Review Agent
The most complex thing I have built so far. An 8-phase pipeline that generates a comprehensive portfolio review:
The Hard Problem: Parent Chain Tracing
To classify KTLO vs Investment work, the agent traces each sprint story → parent Epic → parent Initiative → checks initiative type. Jira returns parent links, but the chain is 3–4 levels deep, each requiring a separate API call. For a 50-story sprint: 150+ API calls just for classification.
Scoped Execution Pattern
This was the first agent I built with partial pipeline support. Saying "portfolio review — just KTLO" executes only phase 4, saving 60–70% of tokens on targeted checks.
- Full 8-phase pipeline: 70–90K tokens (~$5–7 per run)
- Scoped single-phase: 15–25K tokens
I will port this pattern to every heavy agent.
The tool bug audit: The silent Drive-routing bug turned out to affect 6 agents — any agent that searched for meeting transcripts in Drive. Lesson: when you find a tool bug, audit every consumer, not just the one that surfaced it.
Friday — Wiki Hygiene + Knowledge Base Enrichment
Squad Page Auditor
A quarterly audit tool that cross-references the org roster against the team wiki. The pipeline reads the roster, parses the parent wiki page in ADF (Atlassian Document Format), enumerates all child pages, cross-references squad presence, and classifies each as MATCHED / NO_WIKI_PAGE / ARCHIVE_CANDIDATE.
First run results:
- 6 dissolved squads still listed in the wiki — some 2.5 years stale
- 5 new squads missing wiki pages entirely
- 2 squad pages with broken excerpt macros — fixed
- Parent page cleaned: dissolved entries removed, new ones added
ADF Is Brutal
Confluence's Atlassian Document Format is deeply nested JSON. The roster page body was 112K characters of ADF. Parsing requires recursive tree walking, and the structure shifts based on content type — tables, headings, macros, mentions all look different. I wrote 3 versions of the parser before getting it right.
The 80/20 Lesson of the Week
After building a perfect Python script to inject 13 excerpt-include macros into the ADF body, I could not push it back — the payload was too large for the MCP tool parameter limit (117K chars). The solution was a simple instruction table and 3 minutes of manual clicks in the wiki editor.
13 macros × 15 seconds each = 3 minutes manual vs. 2 hours debugging API limits.
Know when to stop.
Persist Knowledge, Do Not Re-query
A Glean MCP query for organizational context returned 132K characters. Instead of running it every conversation, I extracted the key facts and saved them as a reference file. Future conversations get instant access — no API call, no token cost, no auth dependency.
Week 2 By the Numbers
| Metric | Value |
|---|---|
| Total agents | 19 (+2 from week 1) |
| Total skills | 40 (+2) |
| Reports generated | 11 in 5 days |
| New agents built | 2 (portfolio review, wiki auditor) |
| Cross-cutting bugs fixed | 1 (affected 6 agents) |
| Largest agent config | 688 lines |
3 Principles That Emerged This Week
1. Automate the hard part, manual the easy part. The wiki auditor cross-referenced 20+ data sources automatically. The 13 manual clicks were the right call. Automation ROI is about complexity, not volume.
2. Persist expensive queries. If any API returns stable organizational knowledge, query once and save as a reference file. Future conversations get instant, free, auth-independent access.
3. Corporate IT is the real adversary. Not bugs, not API limits — admin policies that silently revoke OAuth grants or block CLI tools mid-day. Build fallback chains. Never assume a tool that worked yesterday works today.
Week 1 was plumbing. Week 2 was intelligence. The agent fleet is becoming a thinking tool, not just a reporting tool.