GPT Image 2.0 Prompt Gallery
A searchable static gallery of GPT Image 2.0 prompts and outputs — mostly curated from the upstream awesome-gpt-image-2-prompts repo, with my own prompting research and examples folded in over time.
GPT Image 2.0 Prompt Gallery
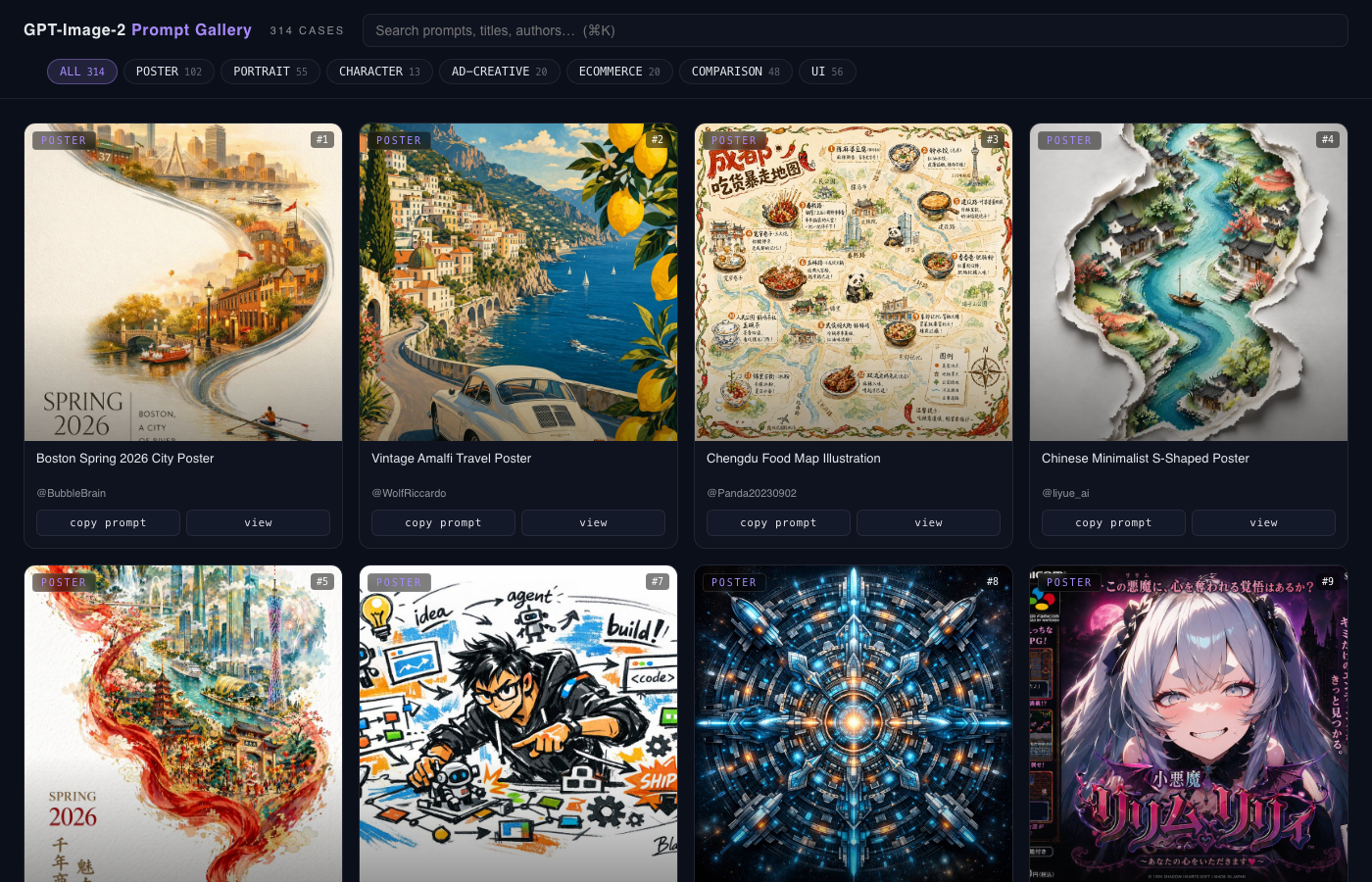
A single-file static browser for GPT Image 2.0 (GPT-4o native image gen) prompts and the images they produced. Live at image2prompt.carlfung.dev · Repo: carlfung1003/image2prompt.
Why this exists
GPT Image 2.0 quietly unlocked a class of AI image generation that earlier models couldn't reliably do. The big one: legible text inside images. Midjourney, Stable Diffusion, even early DALL-E produced mangled, garbled text on signs, posters, packaging, and UI — anything with a word in it required heavy post-editing or just looked broken. GPT Image 2.0 actually renders readable text, and that single capability unlocks a long list of practical workflows: posters, marketing creative, packaging mockups, infographics, e-commerce thumbnails, ad creative, comic panels, and on.
I built this gallery to explore that new design surface — collect strong examples from the community, prototype my own prompts against the same model, and document the patterns that reliably work (and the ones that still don't). Public repos are the starting point; my own experiments in cases-local/ are where I'm figuring out what to actually use it for.
What it is
A merged, browseable, searchable view across multiple public prompt libraries. Each card preserves the original author handle and a link back to source, plus a small badge for which upstream it came from. Filter by source, filter by category (12 buckets), or full-text search across titles, authors, and prompt bodies. Click any card for a full-size view with copy-to-clipboard.
Sources (as of 2026-05-30, ~600 cases total):
| Source | License | What's there |
|---|---|---|
| EvoLinkAI/awesome-gpt-image-2-prompts | CC0-1.0 | Daily batch curation, ~530 cases |
| ZeroLu/awesome-gpt-image | MIT | Hand-picked from X/Twitter creators, ~70 cases |
cases-local/ | (mine) | Own additions, render with a LOCAL badge |
My own additions
This isn't a passive mirror — I add my own prompts and prompting research as I work with the model. Two skills wire it up: image2prompt-add drops a local case into cases-local/, image2prompt-contribute promotes strong locals into a PR upstream. Local cases stay even if they don't make it upstream, so the live gallery is always upstream + my own notebook.
How it's built
build.py runs a per-source parser registry (the SOURCES list) — each source has its own clone target and parser function. Cases get tagged with a source field, namespaced IDs (evolinkai-poster-1, zerolu-photography-3, local-poster-1), and merged into one CASES array that gets inlined into template.html. Output: one static index.html, no JS framework, no runtime fetches.
Adding a new source is mechanical: write parse_<source>(src) returning the standard case dict shape, append to SOURCES. The UI's source-filter chips and category list react automatically.
A launchd plist runs refresh.sh on a schedule — pulls every upstream, rebuilds, deploys via Vercel CLI. The gallery stays current with zero manual effort.
Stack
| Layer | Tool |
|---|---|
| Build | Python (stdlib only) |
| Output | single index.html, ~940KB |
| Search | vanilla JS, in-memory |
| Hosting | Vercel (static) |
| Refresh | launchd cron · bash refresh.sh |
Credits
Prompt content © respective authors via the upstream repos listed above, under their stated licenses. The build pipeline itself (this project's own code) is MIT. Each card preserves the original author handle and a link back to source.